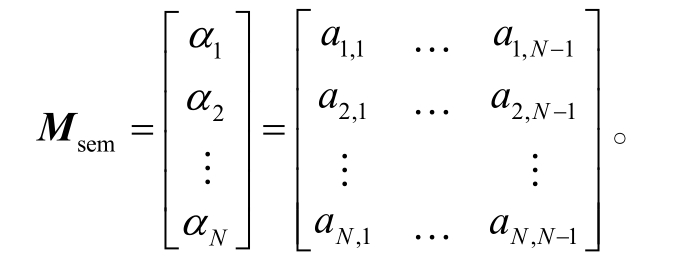
近年来, 基于深度学习的神经网络模型在自然语言处理领域取得突破性进展, 而词向量通常作为模型输入的标准配置。词向量的思想基于分布假说[1],其形式是一个稠密而连续的实数向量。目前训练词向量最常用的方法有 Mikolov 等[2-3]提出的 word2vec以及 Pennington 等[4]提出的 Glove 等, 这些方法在大规模语料中通过目标词和上下文词语的共现训练而得到词向量, 但这种纯粹基于数据驱动进行训练来获取词向量的方法存在性能不稳定[5]、低频词词向量的质量不高[6]等不足。如何将已有的人工知识库结合到词向量的训练中, 以便提升词语向量的表示质量, 成为值得关注的问题。
Hownet[7]等人工知识库是基于离散符号表示,词向量是连续而稠密的。本文提出一种以 Hownet义原向量为基础的词向量表示方法, 将离散形式的人工知识恰当地转化为连续向量表示形式。Hownet 中义原定义为一个最基本的、不易再分割的意义最小的单位, 每个词都可以由若干个义原来组合表示。假定目前Hownet中所有义原之间相互独立且完备, 则每个词语都可视为由其构成的义原向量所张成的子空间内的一个投影, 每个词语的向量表示可以转化为这个词语管辖的所有义原向量的加权平均。通过这种方式, 我们就可以将义原这种离散符号形式表示转换为连续而稠密的数学向量, 这种指定义原向量、通过计算得到词向量的方法更符合语言学定义且高效, 不需要进行训练的初始词向量就可以取得与现有训练方式的词向量相当的效果。进一步在大规模语料中进行训练, 又可以学习到文本中特有的语言现象, 从而得到更好的词向量表示。
本文从 3 个方面对词向量进行评测, 首先选取 3 组高频词和 3 组低频词, 对比基于Hownet的词向量表示和 word2vec 词向量表示的最近邻词语。实验结果表明, 基于Hownet的词向量表示不仅在高频词方面与 word2vec 的效果可比, 而且在低频词方面更加稳定。对词相似度计算和中文词义消歧等标准评测任务进行实验, 并将实验结果与同类研究进行比较, 发现本文方法可以得到更好的效果, 进一步表明对Hownet义原的使用方式、人工知识与词向量表示的结合是切实有效的。
最初的词向量表示为 One-hot 形式, 即每一个词向量只有一个位置, 为 1, 其他均为 0, 且长度与词表等长。这种表示方法存在两个重大的缺陷: 1)语义鸿沟, 即无法通过向量之间的运算来表示语义上的相似度; 2)向量的维度往往与词表长度成正比,所以维度往往很大, 对计算和存储都是一种压力和挑战。
针对上述问题, Rumelhart 等[8]1988年提出将词向量映射到一个低维稠密的语义空间, 每个词向量是一个固定维数的浮点数向量。这种思想很好地弥补了 One-hot 表示中语义鸿沟和维度过大的缺陷。基于这种思想, 又出现诸多训练词向量的模型, 最著名的是 Bengio 等[9]2003年提出的神经网络语言模型(NNLM)以及 Mikolov 等[2-3] 2013年提出的两种词向量训练模型 CBOW 和 Skip-gram。这两种模型都是基于分布假说, 即通过核心词与上下文之间的关系进行建模。不同之处在于, NNLM 为 n-gram 模型, 将一个预设窗口内词语的词向量拼接用来预测目标词; CBOW 将窗口内上下文的词向量相加用于预测目标词, Skip-gram 通过目标词预测上下文。为了解决随语料规模急速增长产生的训练效率低下问题, CBOW 和 Skip-gram 都简化为一种词袋模型(没有将词语间的顺序考虑到建模中), 是更高效的词向量训练方法。
目前, 词向量表示逐渐成为基于深度学习的语言信息处理模型输入的标准配置。
Hownet 是一个中文语义知识库,Hownet体系中一个很重要的工作就是义原的归纳和总结。义原是一个最基本的、不易再分割的意义最小单位, 每个词语都可以由一个或若干个义原来表示, 同一个词的不同义项也由不同的义原组合来表示, 故一个词的表示可以转化为用若干个义原来表示。经过多年发展,Hownet已经非常完善和精炼, 我们采用的Hownet 版本中的义原仅为 2176 个, 能够表示的总词数为 118343 个, 义原总数仅占词表中词总数的1.8%, 如果能够有效地使用这些义原, 性价比将会非常可观。
在引入Hownet义原的研究中, 如何更好地对义原进行表示是关键。唐共波等[10]将义原引入语言模型的训练中, 将大规模语料库中的单义原词语替换为其义原, 然后通过词向量训练模型进行训练,得到义原向量表示, 但是只得到部分义原向量。孙茂松等[6]提出义项敏感模型, 利用这种方法得到Hownet 中全部义原的向量表示。具体做法是, 用CBOW 模型训练得到的词向量, 根据Hownet义原标注得到义原向量, 对于语料中的低频词, 用其管辖的义原向量加和平均来表示。这种方法有效地改善了低频词词向量训练不足的现象。Niu 等[11]提出 SE-WRL 模型, 在义项敏感模型的基础上加入注意力机制, 通过上下文的向量表示, 自动选取当前词的最可能义项, 然后对此义项的义原向量进行调整。以上研究都是通过Hownet 的义原标注, 借助大规模语料训练或根据训练得到的词向量反过来得到义原向量表示, 是一种自上而下的思想。本文首先对义原向量进行建模, 然后通过义原向量表示得到词向量表示, 处理策略是自下而上。
首先, 随机初始化一个义原矩阵Msem:
指定(α1,...,αN)为N个义原对应的义原向量, 每个义原向量为N-1 维, 故义原矩阵Msem是一个N×(N-1)的矩阵。我们假设Hownet中的义原相互独立, 然后根据式(1)对Msem进行施密特正交化:

通过式(2)对(γ1,...,γN)进行单位化:
得到义原正交单位矩阵MsemOrth:
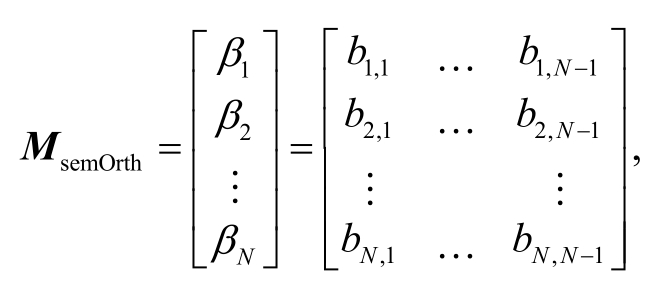
其中, (β1,...,βN)为N组标准正交单位基, 是基于义原独立假设得到的新的义原向量表示。N个义原与N组标准正交单位基一一对应。对N个义原建立“sem-id”索引, 对于每一个义原 sem, 可以得到对应的义原 id, 然后通过 id 进行 look-up 操作, 得到与MsemOrth行号对应的义原向量。至此, 完成 Hownet中义原向量的表示。
根据Hownet中每个词语标注好的对应义原,将每个词语视为由对应的义原向量在这个义原子空间的投影。词语的词向量表示可以由对应的义原向量的加和平均来表示:
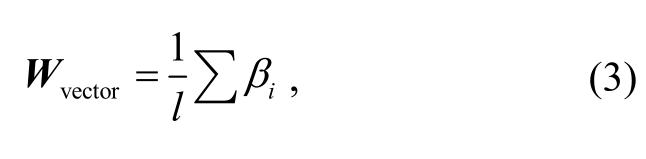
其中,βi为当前词对应的义原向量,l为当前词对应的义原的个数,Wvector即为通过义原向量得到的词向量表示。通过“指定+计算”方法得到的词向量是高效的, 即使未训练, 其效果与 word2vec 也是可比的。在大规模语料上进行训练后, 可以使 Hownet义原标注中的语言学知识与文本中的语言学现象完美结合, 提高了词向量表示的性能。词向量训练模型如图 1 所示。
为了更准确地表述我们的数据结构和模型, 设词表长度为V, 义原数量为N, 最终的词向量维度为D, 上下文窗口大小为k。根据Hownet义原标注体系, 可以构建词-义原索引矩阵Mword-sem:
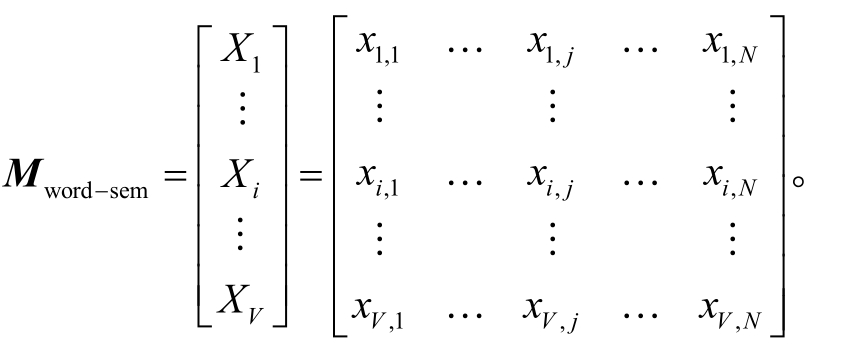

图1 基于Hownet的词向量表示模型架构
Fig.1 Word embedding representation model based on Hownet
对Mword-sem中的元素, 有如式(4)所示的约束:
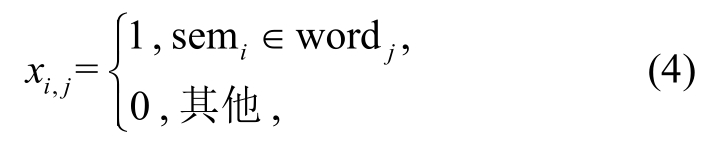
其中,i∈[1,V],j∈[1,N],Mword-sem是V×N的矩阵。2.1 节得到的义原正交单位矩阵MsemOrth为N×(N-1)的矩阵, 对于句子中每个词语wi, 可以通过对应索引得到Mword-sem中的一行Xi=[xi,1...xi,j...xi,N], 再通过式(5)得到每个词的向量化表示Wvector:
Wvector是(N-1)维向量。根据实际需要, 将词向量投影至指定维度D, 如式(6)所示:
Mproject是维度为(N-1)×D的投影矩阵。采用随机初始化, 最终的Wembedding为D维的词向量表示, 这样即可得到目标词上下文中所有词的词向量表示。然后通过式(7), 得到上下文向量表示Wcontext:
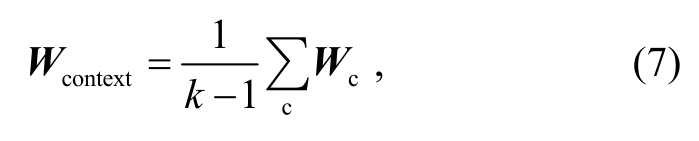
其中,Wc为上下文的各个词的词向量表示,Wcontext是 1×D的矩阵。将Wcontext作为全连接层的输入,通过 softmax 函数得到目标词的预测wt。模型中只有投影矩阵Mproject参与训练。
通常, 词向量训练模型的初始词向量是随机设定的, 没有任何语言学知识的约束。我们的方法是通过Hownet中的义原标注体系, 经过由语言学知识构建的数学模型计算, 得到每个词的词向量, 所以初始词向量具有语言学意义, 从而含义相近的词语的词向量也是相近的。通过这种方式, 我们将义原这种符号主义离散形式的知识转化为连续而稠密的数学模型, 这种指定义原向量, 通过计算得到词向量的方法效率较高, 不需要进行训练的初始词向量, 也可以取得与现有词向量可比的效果。经过在大规模语料上训练后的词向量则结合了语言学规则和上下文假设两个方面的特点, 从而可以得到更好的词向量。
3.1.1 词向量训练数据集
本文词向量训练所用数据集包括 1993—2003年共 11年的《人民日报》新闻语料和搜狗实验室① http://www.sogou.com/labs/resource/ca.php提供的 2012年 6—7 月 18 个频道的新闻语料, 分词后共约 3.5 G, 包括约 5.6亿个词。
3.1.2 词向量训练模型配置
由于Hownet词表中的词是义原标注最准确的部分, 所以目前我们的词向量模型词表以 Hownet词表为主体。首先根据Hownet词表对语料进行分词, 统计后发现,Hownet词表中词的总频次对总词数的覆盖度大约为 91%, 而Hownet词表外的高频词总频次大约占总词频的 7%。对于未登录高频词的部分, 我们所用的分词系统[12]会给这些词一个类别标签: 时间、日期、数字、序数词、人名、地名、商标名、组织机构名以及后缀类型名词。我们将每个类别作为一个义原, 加入现有义原体系中, 属于这 9 类的词视为单义原的词语。对于Hownet词表外的低频词, 统一设定为“UNK”类别, 对应一个“UNK”义原。这样, 我们在未改变Hownet原架构的基础上做了适当的调整, 从而可以更好地结合本文提出的词向量表示模型。
词向量模型的词表大小为 118354, 其中包括Hownet 原词表的 118343 个词语、新增加的 9 个类别标签、1 个“UNK”标识和 1 个“@ZERO”标识(用于神经网络模型的零向量填充)。采用的 Hownet版本的原始义原数量为 2176 个, 增加 9 个类别义原和 1 个“UNK”义原后, 新的义原总数共 2186 个。
模型的训练方式与 Skip-gram 模型相似, 指定窗口大小为 5, 即考虑目标词左右各两个词的大小。义原正交单位矩阵大小为[2186, 2185], 经过投影矩阵得到的词向量维度为 300。模型实现平台为Tensorflow1.2.1, 初始化学习率为 1.0, 优化算法为AdagradOptimizer, 模型训练中的负采样大小为64。
3.1.3 词向量表示对比实验
我们选取语料中 3 个高频词和 3 个低频词, 分别通过 word2vec 和基于Hownet的词向量表示(HWRL)计算这些词语的最近邻词, 结果如表 1 所示。从表1可以得到以下结论。
1)word2vec 的稳定性不强。以“匡正”和“出丑”为例, 虽然 word2vec 可以在其最近邻的词中发现意思相近的词, 但是如果增大其近邻词的范围, 其近义程度降低。对比 H-WRL 在“匡正”这一词的近邻词结果发现, 得益于知识库义原的约束, 即使增大近邻词的范围, 其近邻词在语义上的似性也很强。
2)word2vec 的低频词表示质量不高。根据齐夫定律, 语料中必存在一个庞大的低频词集合, 基于数据的训练方式, 使得 word2vec 对高频词的训练相对较多, 低频词出现次数少, 所以得到的训练较少,如果词频低到一定的程度, 质量就难以保证。通过对比低频词“答理”(百万词频仅为 0.00002)在 word2vec和 H-WRL 的近邻词, 可以发现 word2vec 的近邻词结果是不好的。H-WRL 是基于Hownet义原的, 这些低频词不仅受文本中出现次数的影响, 还受到知识库中已有规则的约束, 因此可以保证低频词的质量。
表1 近邻词计算实验结果
Table 1 Nearest word computation result

?
3)word2vec 基于数据驱动训练方式得到的词向量表示更侧重于语义关联性, 即当前词和近邻词共同出现在一个上下文的情况, 这一现象对“图片”这个词来说最明显。本文模型因为结合了Hownet中的语言学知识, 得到的近邻词更具有语义相似性,即近邻词和当前词是同义词。
词相似度计算任务用于评价词向量的质量, 方法是根据词向量计算给定词对的相似度。
3.2.1 数据集
评价词相似度采用 wordsim-297 标准数据集。此数据集每行的格式都是(w1,w2, score), 其中w1和w2为一对词语, score 为人工评分, 评分区间是0~5。通过式(8)计算给定两个词语的相似度:
其中,d(Embeddingw1, Embeddingw2)为余弦相似度计算。然后, 将 Modelscore正规化到与数据集的人工评分区间相同, 计算 Modelscore与人工评分之间的Spearman 相关系数。
3.2.2 实验结果
词相似度计算的实验结果如表 2 所示, 其中word2vec 是通过 Skip-gram 模型训练得到的词向量,H-WRL 为基于Hownet义原的词向量表示, H-WRLw2v 是将 H-WRL 词向量和 word2vec 词向量进行拼接得到的词向量。我们将 word2vec 作为 baseline,与另外两种模型进行比较。通过表2可以得到以下结论。
1)在 wordsim-297 数据集上, 我们的词向量模型得到的词向量在词相似度计算任务上的结果好于word2vec, 说明我们的词向量表示能够更好地计算词向量表示之间的语义关联。
2)将基于Hownet的词向量表示与 word2vec 的词向量表示进行拼接, 可以提升词向量的整体质量,表明将人工知识与基于训练的词向量进行结合是合理有效的。
表2 任务一词相似度计算实验结果
Table 2 Experimental result of word similarity computation

说明: 粗体数字表示最好结果, 下同。
?
在这部分, 通过词义消歧任务, 对基于 Hownet的词向量表示进行评测。
3.3.1 数据集
评测采用 Senseval-3 的 Task5-Chinese Lexical sample 数据集, 选取数据集中的“把握”、“材料”等6 组词(共 198 个训练例和 96 个测试例)进行评测,这些词的义项数从2到6不等。
3.3.2 实验设置
我们主要对 3 种词向量表示进行测评: word-2vec 词向量、本文提出的基于Hownet义原词向量表示(H-WRL)和将 word2vec 词向量和基于Hownet的词向量进行拼接得到的词向量表示(H-WRL-w2v)。
词义消歧任务的目的是评测不同的词向量表示作为输入时的效果。我们参考目前广泛使用的循环神经网络模型GRU, 模型架构如图2所示。
句子S={wt-4,...,wt,...,wt+4}作为模型的输入, 基于目标消歧词得到两个上下文:Lcontext={wt-4,...,wt}和Rcontext={wt,...,wt+4}。通过词向量索引 look-up操作, 将词向量作为 GRU 的输入, 得到两个输出Lstate和Rstate作为上下文的特征拼接, 经过两个全连接网络层和Softmax 函数进行分类, 得到预测输出。
模型通过 keras 实现, 算法采用十折交叉验证,保证了结果的准确性。模型中词向量的维度为 300(将两种词向量表示进行拼接, 维度为 600), GRU中的节点维度为 100, 全连接网络的隐层节点为100 维, 在两层全连接网络层之间用到 dropout, 参数为 0.1。
在我们的词义消歧任务中随机选择义项作为baseline, 并将实验结果与相关工作(如 Li 等[13]的朴素贝叶斯方法、Wang 等[14]的 PageRank 方法以及孙茂松[6]的义项敏感模型)进行对比, 结果如表 3所示。
3.3.3 实验结果
通过对表 3 进行分析, 可以得出如下结论。
1)本文提出的基于Hownet的词向量表示方法得到的结果是最好的, 表明我们的词向量表示具有一定的词义消歧能力。
2)将 H-WRL 和 word2vec 的词向量进行拼接,提高了 word2vec 词向量的性能, 可见通过知识引入, 可以对word2vec词向量表示进行有效的补充。
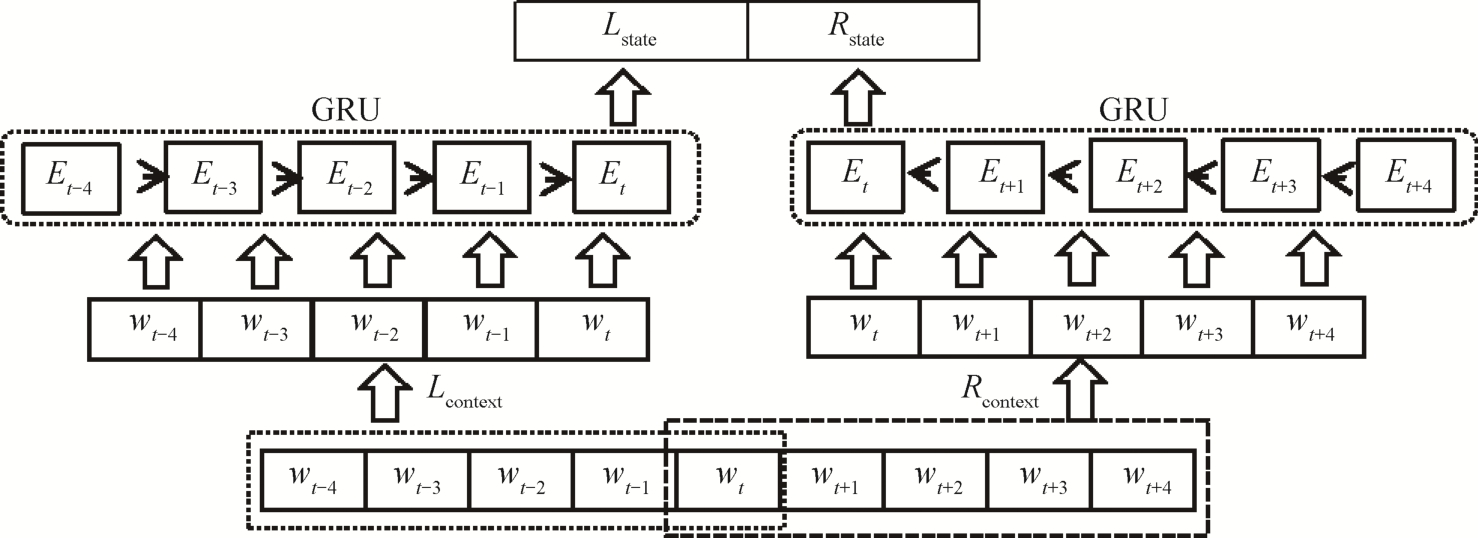
图2 词义消歧模型架构
Fig.2 Word sense disambiguation model
表3 任务二词义消歧实验结果
Table 3 Experimental result of word sense disambiguation result

?
3)在其中的 4 组词中,Hownet的准确率都取得较大的优势, 只有“材料”和“没有”与之前的最好结果相同, 其原因可总结为两点: 第一, “材料”一词只有两个义项, 与其他多义项词相比相对简单; 第二,“没有”在语料中出现的频次高达 51 万次, 属于高频词汇, 在 word2vec 的训练机制中得到充分的训练,故可以有很好的效果。
4)从整体效果来看, 基于Hownet的词向量比基于 word2vec 的词向量性能更稳定, 并且, 基于义原对词向量进行表示的方法不会出现低频词欠缺训练的问题, 故基于Hownet的低频词词向量的质量更高。
本文提出一种基于Hownet的词向量表示方法,基本思想是通过对义原向量进行建模, 将符号主义离散的知识转化为可以连续表示的数学模型。将义原向量化, 所有义原共同构成一个义原向量空间,每个词语可以表示为在这个义原子空间的一个投影。通过这种方式, 我们将人工知识与现有基于训练的词向量表示方法进行有效的结合, 并通过最近邻、词相似度计算以及词义消歧等实验, 对基于Hownet 的词向量表示方法进行测评。测评结果显示, 其结果均好于现有最好结果, 证明这种词向量表示的有效性。总体来说, 基于Hownet义原指定计算得到的词向量表示高效且具有重要的语言学意义, 不仅可以单独作为一种词向量的表示方式, 也可以与基于训练的词向量进行拼接使用, 提升基于训练的词向量表示的性能。
目前, 我们的研究中每个词的表示为这个词管辖下的所有义原。但是, 当这个词为多义词时, 用到的义原应该是不同的, 且这些义原的重要程度也不一样。在未来的工作中, 我们将对义项进行细分,对这些义原的重要程度进行量化研究, 使得基于Hownet 的词向量表示更强大, 可以适用于更多的自然语言处理任务。
[1]Harris Z S.Distributional structure.Word, 1981, 10(2/3): 146-162
[2]Mikolov T, Chen Kai, Corrado G, et al.Efficient estimation of word representations in vector space //ICLR.Scottsdale, 2013: 1-12
[3]Mikolov T, Yih W, Zweig G.Linguistic regularities in continuous space word representations // Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT).Atlanta,2013: 746-751
[4]Pennington J, Socher R, Manning C.Glove: global vectors for word representation // Conference on Empirical Methods in Natural Language Processing.Doha, 2014: 1532-1543
[5]Antoniak M, Mimno D.Evaluating the stability of embedding-based word similarities.Transactions of the Association for Computational Linguistics, 2018,23(6): 107-19
[6]孙茂松, 陈新雄.借重于人工知识库的词和义项的向量表示: 以Hownet为例.中文信息学报, 2016,30(6): 1-6
[7]董振东, 董强.知网[DB/OL].(2000)[2018-04-01].http://keenage.com
[8]Rumelhart D E, Hinton G E, Williams R J.Learning representations by back-propagating errors // Neurocomputing: Foundations of Research.Cambridge, MA MIT Press, 1988: 533-536
[9]Bengio Y, Ducharme R, Vincent P, et al.A neural probabilistic language model.Journal of Machine Learning Research, 2003, 3: 1137-1155
[10]唐共波, 于东, 荀恩东.基于知网义原词向量表示的无监督词义消歧方法.中文信息学报, 2015, 29(6): 23-29
[11]Niu Y, Xie R, Liu Z, et al.Improved word representtation learning with sememes // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.Vancouver, 2017: 2049-2058
[12]罗智勇.现代汉语通用分词系统的技术与实现.北京: 北京工业大学, 2002
[13]Li W, Mccallum A.Semi-supervised sequence modeling with syntactic topic models // National Conference on Artificial Intelligence.Pittsburgh, 2005: 813-818
[14]Wang J, Liu J, Zhang P.Chinese word sense disambiguation with PageRank andHownet// IJCNLP.Hyderabad, 2007: 39-44
A Word Representation Method Based on Hownet