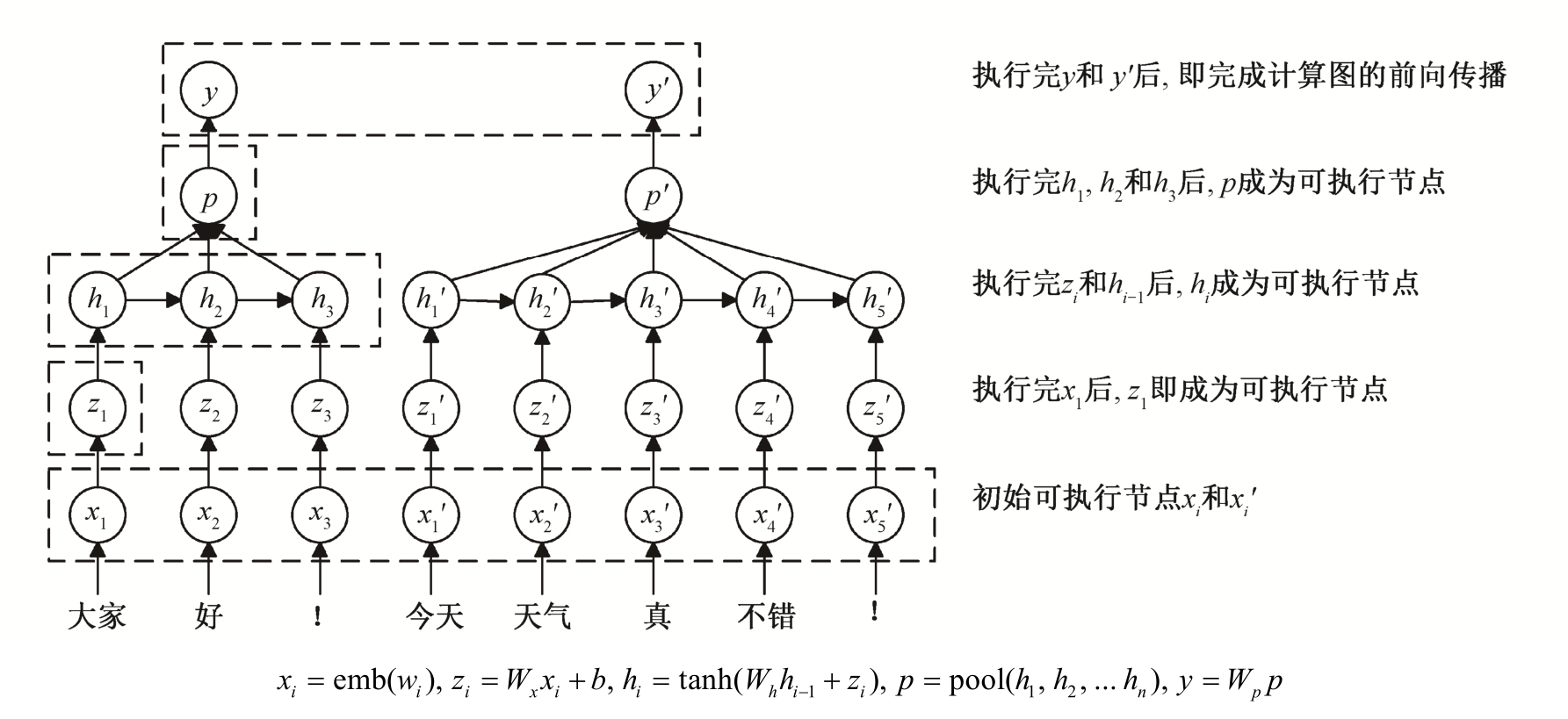
图1 一种RNN模型
Fig.1 An RNN model
近年来, 深度学习方法在自然语言处理领域很多任务中的性能超越了传统的统计机器学习方法,得到广泛的应用[1]。在训练阶段, 深度学习模型的执行步骤包括前向传播、反向传播和更新参数等,深度学习库能方便地执行这些步骤。Theano[2]、CNTK[3]、Caffe[4]、TensorFlow[5]和PyTorch[6]等已得到广泛的应用[7-10]。
Theano[2]、CNTK[3]、Caffe[4]和TensorFlow[5]在训练前静态地定义计算图, 在训练时对所有实例执行同一个计算图。然而, 在自然语言处理任务中,构建适应所有实例的计算图存在额外的困难, 体现在以下两方面。
1)各实例的长度不一致。补零可使各实例长度一致, 然而补零操作可能影响计算结果。为了避免这个影响, 需对计算结果做裁剪。
2)实例含有结构化信息, 如句法结构。有时我们希望基于这些结构化信息动态地构建计算图, 比如在基于句法的递归神经网络中, 不同的句子实例有着不同的句法结构, 也就对应不同的计算图。
PyTorch等深度学习库则根据不同的实例, 动态地构建不同的计算图。为了利用多核CPU或GPU加速计算, PyTorch要求使用者将可以批量化计算的数据手动合并为张量。比如在计算机视觉任务中,使用者须将多个图像实例合并为一个张量后作为模型的输入。
然而, 在自然语言处理任务中, 手动批量化合并数据存在以下额外的困难: 1)各句子实例须在补零后才能合并为张量; 2)在树结构模型(如递归神经网络)中, 须分析计算图执行步骤后, 将同一执行步骤中处于不同实例上的计算过程批量化。
Looks等[11]提出一种自动批量化方法, 允许深度学习库构建完整个计算图后, 自动地发现当前可执行的同类型计算过程, 并将其批量化执行。为方便自然语言处理领域的研究者使用, 我们也实现了动态计算图和自动批量化。如同多数深度学习库[2-6],我们还实现了自动微分。N3LDG将向量视为计算的对象, 将卷积、池化等视为基于向量的各种操作,而在自然语言处理任务中, 深度学习模型的输入通常是词向量, 或拼接了其他特征的向量, 这样N3LDG满足了自然语言处理任务的要求。为提高执行速度, N3LDG使用C++语言来实现。与其他深度学习库相比, N3LDG更容易使用, 只需在项目中包含头文件即可使用。在Apache 2.0协议下, N3LDG在https://github.com/zhangmeishan/N3LDG发布。
近年出现很多通用深度学习库。Zhang等[12]提出一种自然语言处理深度学习库LibN3L, 实现深度学习模型中的常见操作, 但是该库不支持自动批量化。针对深度学习模型的计算图的自动批量化研究尚不多见。Looks等[11]首先提出基于节点在计算图中的深度的自动批量化方法后, Neubig等[13]认为这个方法在处理RNN模型时难以充分批量化。为缓解这个问题, Neubig等[14]提出一种将同类型节点在计算图中的平均深度作为启发式规则的方法, 并应用在他们的深度学习库DyNet中。由于RNN模型在自然语言处理任务中较常用, 为了高效地训练RNN模型, 我们仿照Neubig等[13]的方法。
多数的深度学习库能够利用GPU加速训练模型[2-6,14]。Chetlur等[15]提出cuDNN库, 高效地实现深度学习中的各基本操作。为了高效地分配显存,DyNet在库初始化时创建了3个显存块[14], 其中一个显存块在前向传播中使用, 另一个在反向传播中使用, 最后一个用于存储参数和相关的梯度。这样,可通过指针的加减运算, 实现分配和释放显存的操作。我们利用显存池来高效地分配显存, 这种做法不要求使用者预估显存占用空间, 而是在需要时动态地向系统申请新的显存块。
对于一个简单的线性分类器y=Wx, 只需以x为自变量做线性变换, 便可得到分类结果。为说明计算图的优点, 我们引入更复杂的模型。图1描述一种循环神经网络(RNN)模型。该模型可表示为y=f(x1,x2, …,xn), 我们难以直接表示f, 因此将f分解为多个简单的计算步骤, 每步计算结果存储在一个中间向量中。将向量视为图的节点, 向量之间形成有向边, 分解后的各计算步骤和向量构成计算图G。
图1 一种RNN模型
Fig.1 An RNN model
为实现计算图, 首先定义Node类作为计算图节点。以图1中hi=tan h (Whhi-1+zi)为例, 为了计算hi,Node类需包含以下信息: 1)前向传播的计算方法;2)本节点向量(hi); 3)各输入向量(hi-1,zi); 4)参数(Wh)。当给定各输入向量x1,x2, …,xn时, 某节点即可执行前向传播过程, 求得本节点向量y=f(x1,x2, …,xn), 称该节点为可执行节点。y又可作为其子节点的输入向量, 使子节点成为可执行节点。若某节点不含输入向量(如图1中xi所在节点), 则该节点成为计算图G的初始可执行节点。这样, 以初始可执行节点为始, 重复执行前向传播过程, 直至计算图中所有节点都被执行, 即完成模型的前向传播过程。图 1 描述了这个过程。
为执行反向传播, Node类还须包含以下信息: 1)反向传播的计算方法; 2)损失函数L对y的导数![]() ;3)L对各输入向量的导数
;3)L对各输入向量的导数![]() 4)L对各参数的导数
4)L对各参数的导数![]() 我们在Node类中定义前向传播和反向传播的接口, 在其各个子类中实现这两个接口。我们实现了常用的节点类型,包括tanh, concat和线性变换等, 列举在表 1 中。使用者也可自己定义新的节点类型, 实现前向传播和反向传播。
我们在Node类中定义前向传播和反向传播的接口, 在其各个子类中实现这两个接口。我们实现了常用的节点类型,包括tanh, concat和线性变换等, 列举在表 1 中。使用者也可自己定义新的节点类型, 实现前向传播和反向传播。
表1 N3LDG中的常用节点类型
Table 1 Commonly used node types in N3LDG

?
计算图中往往有多个可执行节点。为了提高执行速度, 需要批量化地执行同类型的计算过程。具体而言, 有两类计算过程可批量化执行: 1)共享参数的同类型计算, 如y1=Wx1+b和y2=Wx2+b; 2)不含参数矩阵的同类型计算, 如y1=tanh(x1)和y2=tanh(x2)。
N3LDG自动发现当前可执行节点, 并批量化执行同类型的计算过程。当这些节点被执行完后, 即从计算图中移除, 此时可得新的可执行节点集合。这样, 我们总能得到当前可执行节点的集合, 直到计算图执行完毕。以图1中RNN模型为例, 执行步骤如下。
1)[x1x2… ]=[emb(大家)emb(好)… emb(!)]
]=[emb(大家)emb(好)… emb(!)]
2)[z1z2…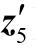 ]=Wx[x1x2…
]=Wx[x1x2… ]+[b b…b]
]+[b b…b]
3)[h1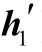 ]=tanh([z1
]=tanh([z1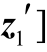 )
)
4)[h2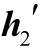 ]=tanh(Wh[h1
]=tanh(Wh[h1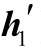 ]+[z2
]+[z2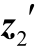 ])
])
5)[h3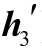 ]=tanh(Wh[h2h2′]+[z3
]=tanh(Wh[h2h2′]+[z3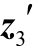 ])
])
6)![]()
7)![]()
8)[p p′ ]=[pool(h1,h2,h3)pool![]()
9)[y y′ ]=Wp[p p′]
当遇到同时有多种计算过程可执行时, 比如执行完![]() 后, 既可执行
后, 既可执行![]() , 也可执行p=pool(h1,h2,h3),为了批量执行池化操作, 应先执行
, 也可执行p=pool(h1,h2,h3),为了批量执行池化操作, 应先执行![]()
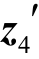 )。我们参照Neubig等[13]的方法, 对某计算类型的节点求平均深度, 以此作为启发函数, 优先执行平均深度更小的计算过程。
)。我们参照Neubig等[13]的方法, 对某计算类型的节点求平均深度, 以此作为启发函数, 优先执行平均深度更小的计算过程。
Eigen是通用的C++线性代数计算库[16], 因此我们使用Eigen实现CPU上的线性代数计算。由于CPU能高效地处理内存中连续存放的向量, 所以N3LDG对常用的计算过程做了优化。具体的步骤如下: 1)计算前, 将各节点中的输入向量合并为一个矩阵, 将矩阵与多个向量的乘法运算转换为矩阵与矩阵的乘法运算; 2)执行矩阵和矩阵的乘法运算,得到结果矩阵; 3)将该结果矩阵拆分后, 赋值给各节点的向量。
我们以y1=tanh(Wx1+b),y2=tanh(Wx2+b)...yn=tanh(Wxn+b)为例, 首先将x1,x2,…,xn合并为矩阵[x1x2…xn], 记为X, 将同一个向量b扩展为n列矩阵[b b...b], 记为B。将各向量拷贝至连续的内存区域中, 然后执行Y=tanh(WX+B), 计算完成后,将矩阵Y拆分拷贝至各节点的向量。
cuBLAS是英伟达发布的CUDA线性代数计算库, 我们使用cuBLAS实现GPU上的线性代数计算,并编写kernel函数实现其余计算过程。为充分利用GPU的并行计算能力, 我们并行执行所有批量化之后的计算过程。我们的实现不依赖cuDNN[15], 使用者无需安装cuDNN。
我们发现GPU中有两类操作存在性能瓶颈: 1)显存分配与释放; 2)显存和内存间的I/O。当动态构建计算图时, 参与前向传播和反向传播计算过程的各向量地址也随之动态地变化, 计算前, 须将这些信息传输到显存, 这会频繁涉及上述两类操作。我们通过以下方法来缓解性能瓶颈。
在实验中测量显存的分配与释放时间, 发现它们占总训练时间相当大的比例, 成为性能瓶颈。通过专用模块(显存池), 持有并管理空闲的显存块,当不持有合适的空闲块时, 才向系统申请显存块,从而减少向系统分配与释放显存的次数。英伟达实现了显存池库cnmem, 在https://github.com/NVIDIA/cnmem发布。Knowlton等[17]提出伙伴系统, 用于快速分配存储空间。受伙伴系统启发, 我们也实现了显存池。
对于同样大小的数据, 只调用一次库函数, 将其传输至显存, 显著地快于分成多次传输[18]。因此,对需传输至显存的多个数据, 我们在内存中将其连续存放后, 再调用一次库函数传至显存。比如, 批量化执行y1=tanh(x1),y2=tanh(x2)...yn=tanh(xn)时, 需将x1,x2, …,xn的地址传输至显存, 我们在内存中连续存放x1,x2, …,xn的地址后, 调用一次库函数, 将这些地址传输至显存。与调用多次库函数而分别传输它们的地址相比, 我们的方法显著地减少了显存与内存间的I/O次数。
我们通过一个 5 分类情感分类任务, 在 3 个模型上做基准测试: 1)卷积神经网络(CNN); 2)双向长短时记忆网络(Bi-LSTM); 3)树结构长短时记忆网络(Tree-LSTM)[19]。以上模型的词向量和隐层的维度都设置为200。训练数据包括8544个句子实例,共163563个词(包括标点符号), 测试代码在https://github.com/chncwang/n3ldg-benchmark发布。记录训练一轮epoch的时长, 包括: 1)构建计算图; 2)规划执行步骤; 3)前向传播; 4)反向传播; 5)更新参数。实验中, CPU的型号是Intel (R)Core (TM)i7-6800K CPU @ 3.40 GHz, GPU型号是GeForce GTX 1080 Ti。我们还用PyTorch实现一致的模型结构,并在 3 个模型上实现手动批量化, 以便与N3LDG对比训练速度。在N3LDG中, 我们未对LSTM做特别的优化, 为公平对比, 用PyTorch以同样方式实现LSTM。
首先在单线程CPU上, 对N3LDG和PyTorch做基准测试, 测试结果见表2。
表2 显示, 在所有设置下, N3LDG在单线程CPU上的训练速度高于PyTorch。当我们训练CNN时,N3LDG训练速度达到PyTorch的9.40~42.47倍, 训练Bi-LSTM时达到PyTorch的4.43~9.71倍, 训练Tree-LSTM时达到PyTorch的1.28~3.10倍。这表明我们构建计算图、自动批量化和CPU计算过程是高效的。
表2 单线程CPU上N3LDG和PyTorch的基准测试
Table 2 Benchmarks of N3LDG and PyTorch on single thread CPU
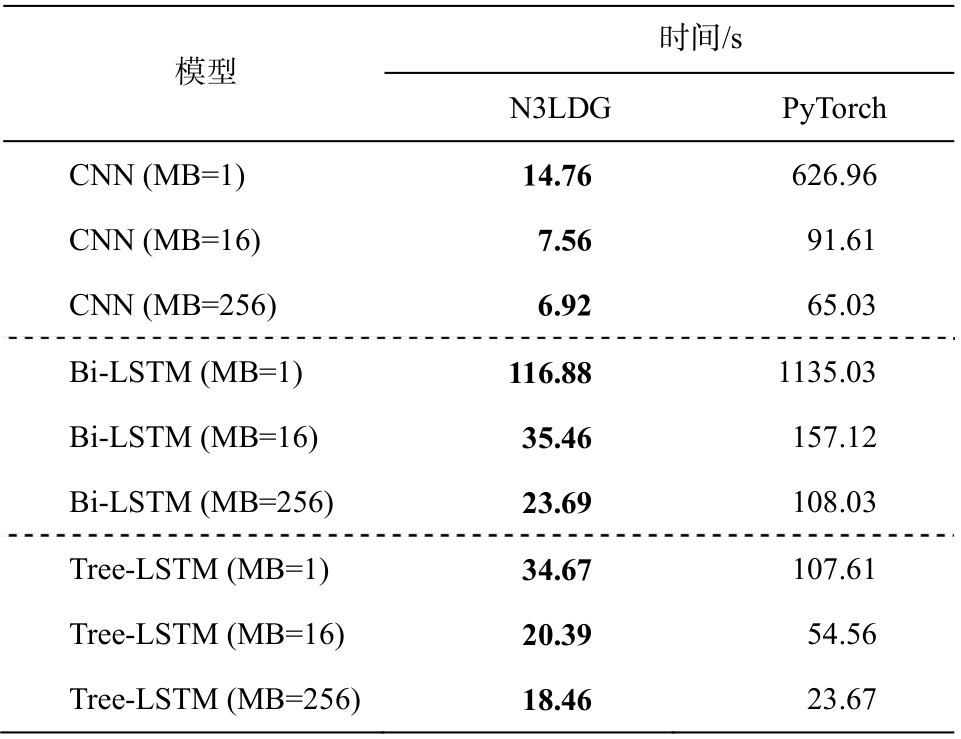
说明: MB表示mini-batch大小; 粗体数字表示最好结果, 下同。
?
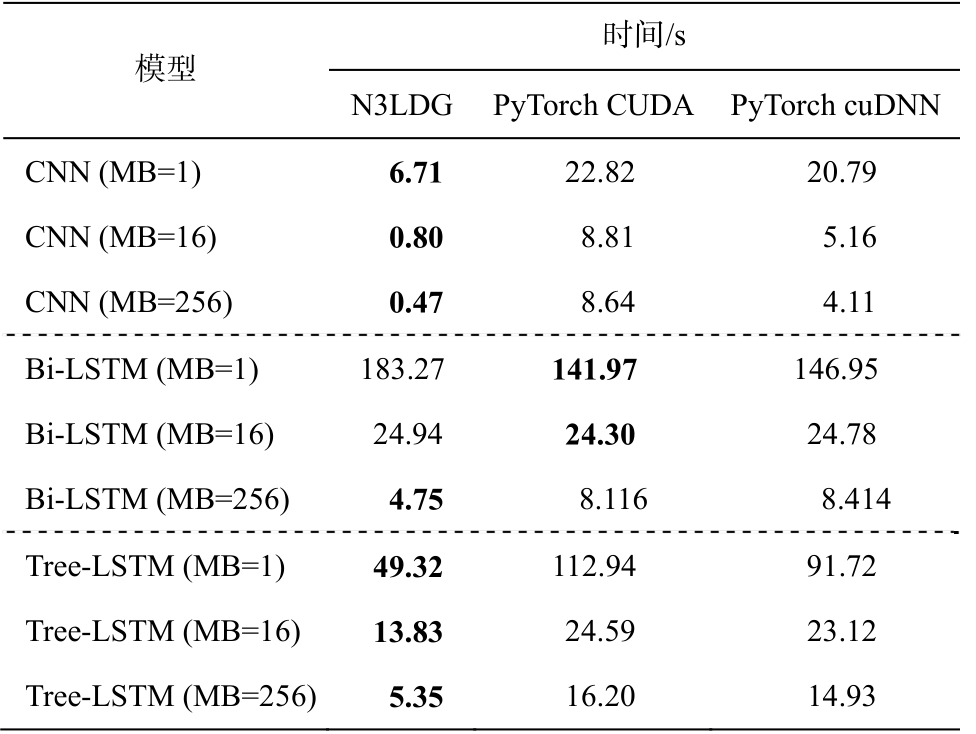
我们在GPU上对N3LDG、不使用cuDNN的PyTorch (称为PyTorch CUDA)以及使用cuDNN的PyTorch (PyTorch cuDNN)做了基准测试, 测试结果见表 3。
表3 显示, 在训练CNN和Tree-LSTM时, N3LDG在GPU上的训练速度高于PyTorch CUDA和PyTorch cuDNN。在训练CNN时, N3LDG的训练速度达到PyTorch CUDA的3.40~18.38倍, PyTorch cuDNN的3.10~8.74倍, 训练Tree-LSTM时速度达到PyTorch CUDA的1.78~3.03倍, PyTorch cuDNN的1.67~2.79倍。训练Bi-LSTM模型时, N3LDG在较大的minibatch下有优势。当mini-batch=1时, N3LDG的训练速度低于PyTorch, 是PyTorch CUDA的77.46%,PyTorch cuDNN的80.18%。当mini-batch=16时,N3LDG的训练速度与PyTorch几乎相同。当minibatch=256时, N3LDG的训练速度达到PyTorch CUDA的1.71倍, PyTorch cuDNN的1.77倍。总体而言, 我们构建计算图、自动批量化和GPU计算过程是高效的。
为了分析自动批量化对训练速度的影响, 以Bi-LSTM (MB=256)为例, 分别在单线程CPU和GPU上测试是否做自动批量化时各步骤的时长。实验结果见图 2。
图2显示, 自动批量化显著地提升了训练速度。在单线程CPU上提升4.76倍, 在GPU上提升52.27倍。提速主要来自前向传播和反向传播。
我们猜测在单线程CPU上提速的部分原因在于合并了矩阵与向量的乘法, 比如将y1=Wx1和y2=Wx2转换为[y1y2]=W[x1x2]后, 计算速度更快。我们还对比了在相同设置下, 一轮epoch中矩阵乘法的总执行时间、执行次数及平均执行时间, 结果见表 4。
表3 GPU上N3LDG, PyTorch CUDA和PyTorch cuDNN的基准测试
Table 3 Benchmarks of N3LDG, PyTorch CUDA and PyTorch cuDNN on GPU
?
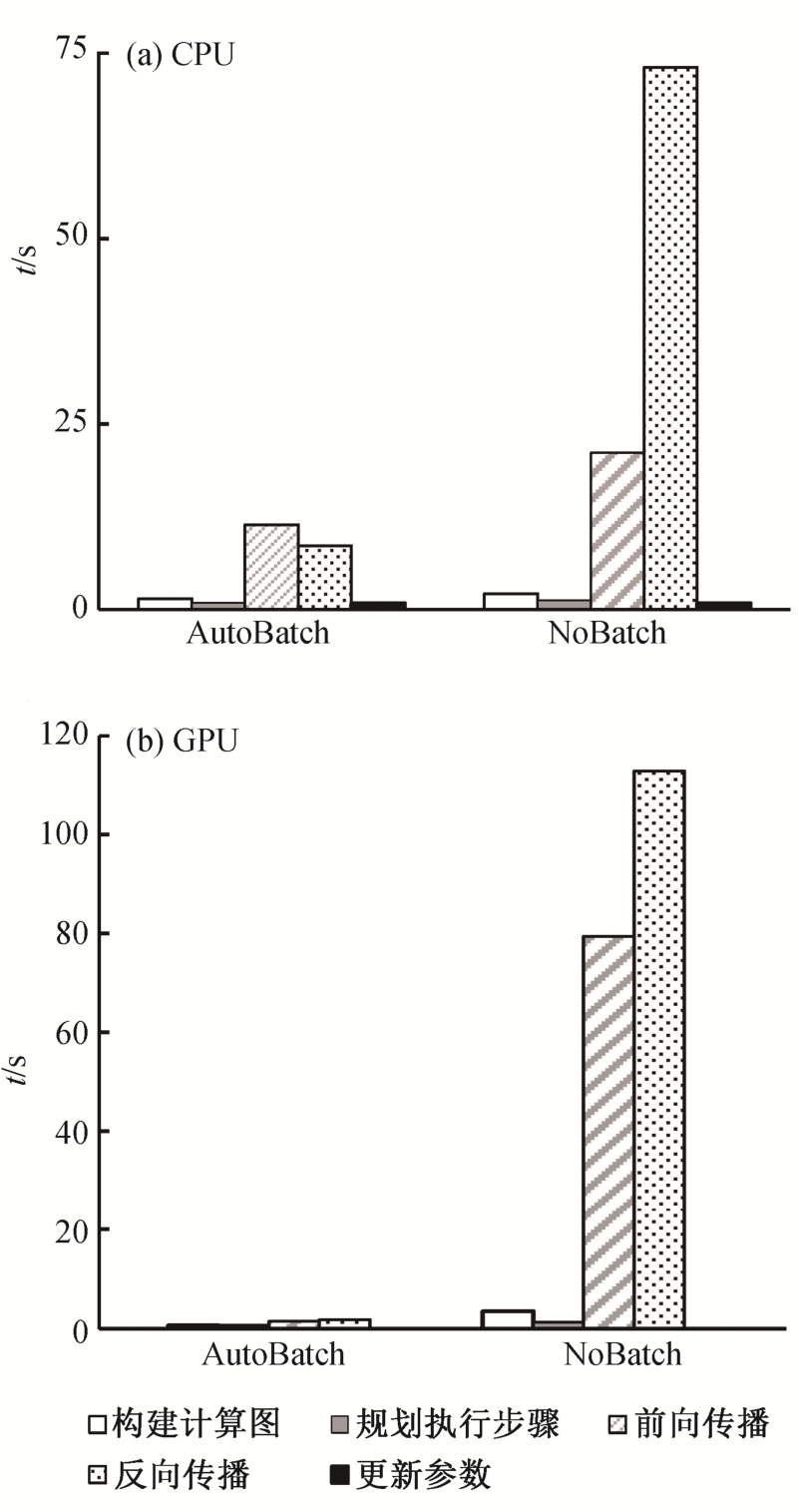
图2 做自动批量化与否时各训练阶段时长
Fig.2 Time in per training stage when auto-batch enabled or not
表4 显示自动批量化显著地提升了单线程CPU矩阵乘法的执行速度, 提升幅度为9.28倍。与不做批量化相比, 尽管自动批量化时平均执行时间更长,但执行次数仅为0.98%。
为分析自动批量化对CUDA核函数执行速度的影响, 我们对比了在相同设置下, 一轮epoch中核函数的总执行时间、执行次数及平均执行时间, 结果见表 5。
表5 显示, 自动批量化显著提升了CUDA核函数的执行速度, 提升幅度为70.52倍。与不做批量化相比, 执行次数仅为1.28%。值得注意的是, 平均执行时间只是不做批量化时的1.11倍, 表明自动批量化充分利用了GPU的并行计算能力。
表4 单线程CPU矩阵乘法的总执行时间、执行次数和平均执行时间
Table 4 Total execution duration, times and average duration of matrix multiplication

?
表5 CUDA核函数的总执行时间、执行次数和平均执行时间
Table 5 Total execution duration, times and average duration of CUDA kernel functions
?
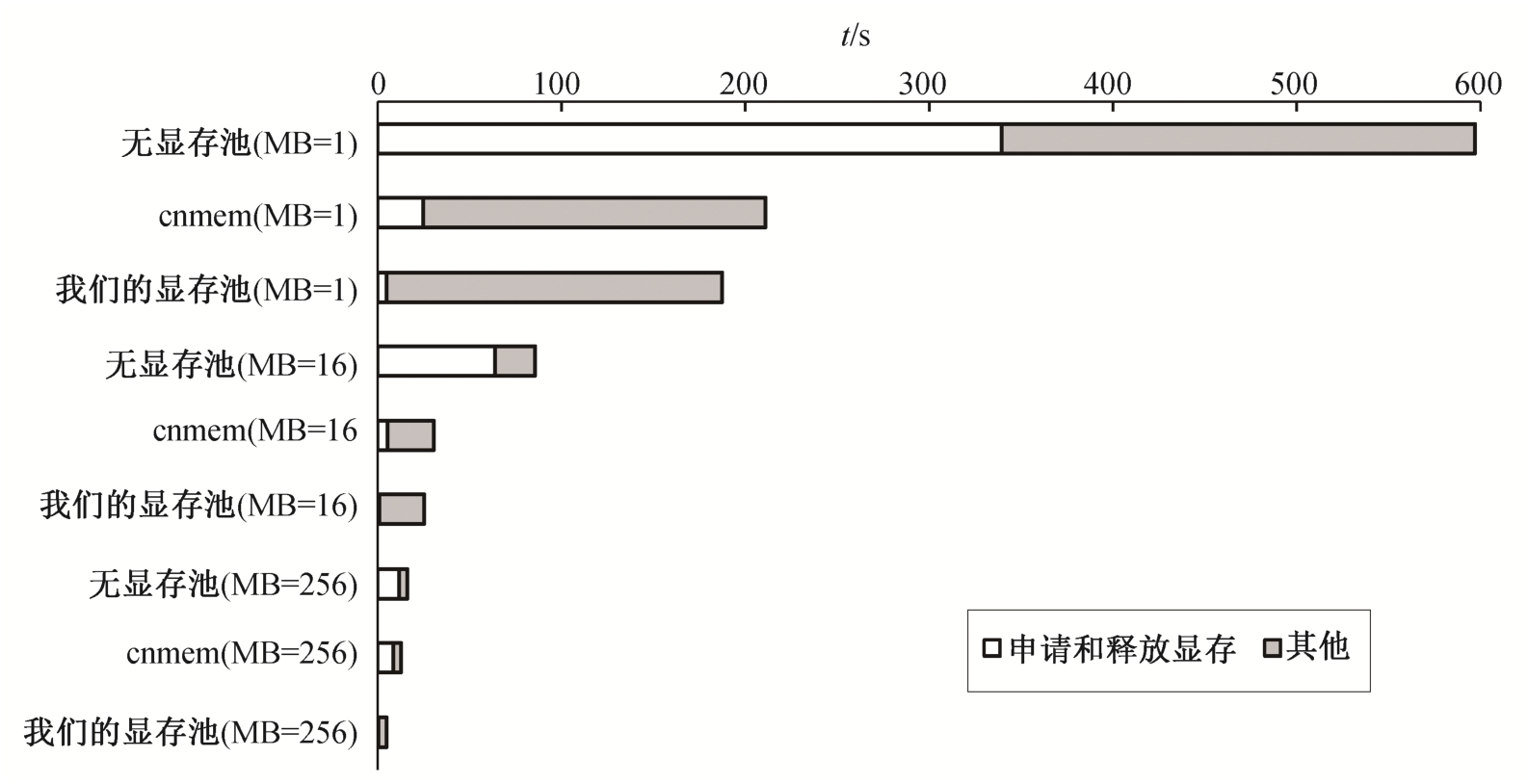
图3 无显存池、cnmem和我们的显存池训练时间对比
Fig.3 Comparison of training time among the absence of the memory pool, cnmem and ours
为测试显存池的有效性, 我们在训练Bi-LSTM时, 分别统计一轮epoch中, 不使用显存池、使用cnmem以及使用我们的显存池时的训练时间以及分配与释放显存的时长, 实验结果见图 3。
图3 显示, 当不使用显存池时, 显存的分配与释放占训练时间的56.87%~74.72%, 成为性能瓶颈,而显存池显著降低时长。使用我们的显存池时, 分配与释放显存的速度是使用cnmem时的5.11~37.11倍, 训练速度是无显存池时的3.19~3.37倍, 使用cnmem时的1.13~2.63倍, 表明我们的显存池是高效的。
为方便在自然语言处理任务中应用深度学习,移除手动批量化过程, 本文提出一种轻量级自然语言处理深度学习库N3LDG。我们仿照Neubig等[13]的方法, 实现自动批量化, 并在CPU和GPU上都高效实现常见的深度学习计算过程。实验表明, 自动批量化显著提高了CPU和GPU上的执行速度。我们的库在CNN, Bi-LSTM和Tree-LSTM模型中的CPU性能以及在CNN和Tree-LSTM模型中的GPU性能都优于PyTorch。作为一种轻量级的库, 我们开发的N3LDG为自然语言处理领域的研究者提供了新的选择。
[1]Young T, Hazarika D, Poria S, et al.Recent trends in deep learning based natural language processing [EB/OL].(2017-08-09)[2018-04-01].https://arxiv.org/abs/1708.02709
[2]Team T T D, Al-Rfou R, Alain G, et al.Theano: a python framework for fast computation of mathematical expressions [EB/OL].(2016-03-09)[2018-04-01].https://arxiv.org/abs/1605.02688
[3]Yu D, Eversole A, Seltzer M, et al.An introduction to computational networks and the computational network toolkit.Microsoft Technical Report MSR-TR-2014-112.Singapore, 2014
[4]Jia Y, Shelhamer E, Donahue J, et al.Caffe: convolutional architecture for fast feature embedding // Proceedings of the 22nd ACM international conference on Multimedia.Orlando, 2014: 675-678
[5]Abadi M, Barham P, Chen J, et al.Tensorflow: a system for large-scale machine learning // OSDI.Savannah, 2016: 265-283
[6]Paszke A, Gross S, Chintala S, et al.Automatic differentiation in pytorch // NIPS 2017 Autodiff Workshop: The Future of Gradient-based Machine Learning Software and Techniques.Long Beach, 2017: 1-4
[7]Bahdanau D, Cho K, Bengio Y.Neural machine translation by jointly learning to align and translate[EB/OL].(2014-09-01)[2018-04-01].https://arxiv.org/abs/1409.0473
[8]Chen Z, Droppo J, Li J, et al.Progressive joint modeling in unsupervised single-channel overlapped speech recognition.IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2018,26(1): 184-196
[9]Simonyan K, Zisserman A.Very deep convolutional networks for large-scale image recognition [EB/OL].(2014-09-04)[2018-04-01].https://arxiv.org/abs/1409.1556
[10]Chen L C, Papandreou G, Kokkinos I, et al.Deeplab:semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRTs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848
[11]Looks M, Herreshoff M, Hutchins D L, et al.Deep learning with dynamic computation graphs [EB/OL].(2017-02-07)[2018-04-01].https://arxiv.org/abs/1702.02181
[12]Zhang M, Yang J, Teng Z, et al.LibN3L: a lightweight package for neural NLP // LREC.Paris,2016: 225-229
[13]Neubig G, Goldberg Y, Dyer C.On-the-fly operation batching in dynamic computation graphs [EB/OL].(2017-05-22)[2018-04-01].https://arxiv.org/abs/1705.07860
[14]Neubig G, Dyer C, Goldberg Y, et al.Dynet: the dynamic neural network toolkit [EB/OL].(2017-01-15)[2018-04-01].https://arxiv.org/abs/1701.03980
[15]Chetlur S, Woolley C, Vandermersch P, et al.Cudnn:efficient primitives for deep learning [EB/OL].(2014-10-03)[2018-04-01].https://arxiv.org/abs/1410.0759
[16]Guennebaud G, Jacob B.Eigen [EB/OL].[2018-04-01].http://eigen.tuxfamily.org
[17]Knowlton K C.A fast storage allocator.Communications of the ACM, 1965, 8(10): 623-624
[18]Fatica M, LeGresley P, Buck I, et al.High performance computing with CUDA.Tutorial in IEEE Supercomputing, 2007, 18 (6): 397-412
[19]Tai K S, Socher R, Manning C D.Improved semantic representations from tree-structured long short-term memory networks [EB/OL].(2015-02-28)[2018-04-01].https://arxiv.org/abs/1503.00075
N3LDG:A Lightweight Neural Network Library for Natural Language Processing