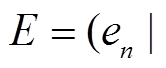
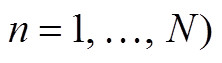 代表路段的集合,
代表路段的集合, 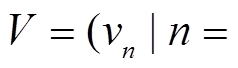
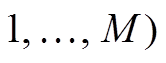 代表路段端点的集合。每条路段除包含首尾节点和中间节点的坐标信息外, 也包含交通规则约束(如单行、双行)等属性信息[12]。
代表路段端点的集合。每条路段除包含首尾节点和中间节点的坐标信息外, 也包含交通规则约束(如单行、双行)等属性信息[12]。刘旻 李梅† 徐晓宇 毛善君
北京大学地球与空间科学学院, 北京 100871; † 通信作者, E-mail: mli@pku.edu.cn
摘要 针对轨迹数据在线地图匹配中难以同时保障算法的准确率和时间效率的问题, 提出一种基于隐马尔科夫模型(HMM)改进的在线地图匹配算法, 并提出综合距离因素和方向因素计算发射概率的方法。与其他全局或者局部算法的不同之处在于, 改进的在线地图匹配算法引入可靠点进行轨迹分割, 减少了转移概率的计算和匹配结果的输出延时。用西雅图市浮动车的轨迹数据进行算法的实验验证, 结果表明, 与传统的HMM地图匹配算法相比, 改进的算法在准确率和时间效率上更优, 能够满足在线地图匹配的需求。
关键词 地图匹配; 隐马尔科夫模型(HMM); 可靠点; 转移概率; 发射概率
随着无线通信技术和定位技术的发展, 全球定位系统(Global Positioning System, GPS)广泛应用于车辆及智能终端, 获取了大量的轨迹数据(移动对象在某时段内通过采样获取的信息, 一般包含位置、时间和速度等属性), 可用于空间数据挖掘、智能交通[1–3]、城市计算[4–5]等领域。由于城市道路情况复杂以及建筑物或隧道遮挡信号等因素的影响, 轨迹数据通常存在误差, 需要运用地图匹配技术将轨迹点匹配到正确的道路上。
地图匹配算法使用的信息可分为 4 类: 几何信息、拓扑信息、概率信息和综合信息[6]。在使用几何信息方面, 通常是点到线的简单算法, 直接将轨迹点匹配到最近的路段上, 此类算法未考虑路段之间的连通性, 虽然效率高, 但精度较差。在使用拓扑方面, 李清泉等[7]基于拓扑约束构建候选路段集合, 利用最短路径算法进行地图匹配。在使用概率信息方面, Ochieng 等[8]基于概率信息, 提出一种针对复杂道路网络的地图匹配算法。在使用综合信息方面, 主要使用机器学习或数据挖掘方法, Newson等[9]提出一种基于隐马尔科夫模型(Hidden Markov Model, HMM)的算法。该算法是一种全局匹配算法, 基于拓扑约束获取最佳的道路序列。使用综合信息的地图匹配算法准确率相对较高, 但数学计算复杂, 速度较慢。
按照考虑的轨迹范围, 地图匹配算法可分为局部算法和全局算法。局部算法是根据距离和方向的相似性选取局部最优路段, 计算速度较快, 一般用于在线匹配, 处理采样率高的轨迹时效果较好, 匹配采样率较低的轨迹时准确率较低。全局算法考虑整条轨迹, 目标是从路网中找到与轨迹最相似的路段序列, 其中很多算法使用“Frechet 距离”或“弱Frechet 距离”计算轨迹与匹配路段的相似性[10]。与局部算法相比, 全局算法计算效率低, 但准确率高。
在线地图匹配问题是目前研究的热点。在在线地图匹配场景中, 难以同时保障算法准确率和时间效率, 需要选取合适尺寸的算法窗口。如果算法窗口尺寸过小, 则算法的准确率较低; 如果算法窗口的尺寸过大, 则匹配结果输出延时较长。
本文针对上述问题, 将全局匹配与局部匹配的思想相结合, 提出改进的 HMM 地图匹配算法, 主要贡献是提出可靠点的概念。基于可靠点, 将整条轨迹分成不同的增量, 将每个增量作为一个窗口, 在增量内, 基于 HMM 模型计算轨迹的全局最优路径。可靠点处的候选路段集只包含发射概率最高的路段, 减少转移概率矩阵的计算, 缩短在线匹配时结果输出的延迟, 从而提高算法的时间效率。综合考虑距离和方向两个因素, 进行发射概率评估。基于可靠点, 保证增量首尾处匹配的准确性和算法的准确率。
地图匹配(map matching)指将行车轨迹的经纬度采样序列与数字地图路网匹配的过程, 其本质是平面线段序列的模式匹配问题[11]。
轨迹数据存在一定的误差, 使用地图进行可视化时往往不在道路上, 地图匹配的目的即找到轨迹点对应的路段。图 1 为地图匹配的示意图, 采样获取的 GPS 轨迹数据为(p1, p2, p3, p4)。在复杂的道路交通网络中, GPS 的误差较大, 且候选路段众多, 图 1 中轨迹点 p2 距离正确匹配路段较远,距离错误匹配路段较近,如果直接将轨迹点简单地匹配到最近的道路, 则容易出错。
道路网络由一个有向图 G(V, E)表示。代表路段的集合, 代表路段端点的集合。每条路段除包含首尾节点和中间节点的坐标信息外, 也包含交通规则约束(如单行、双行)等属性信息[12]。
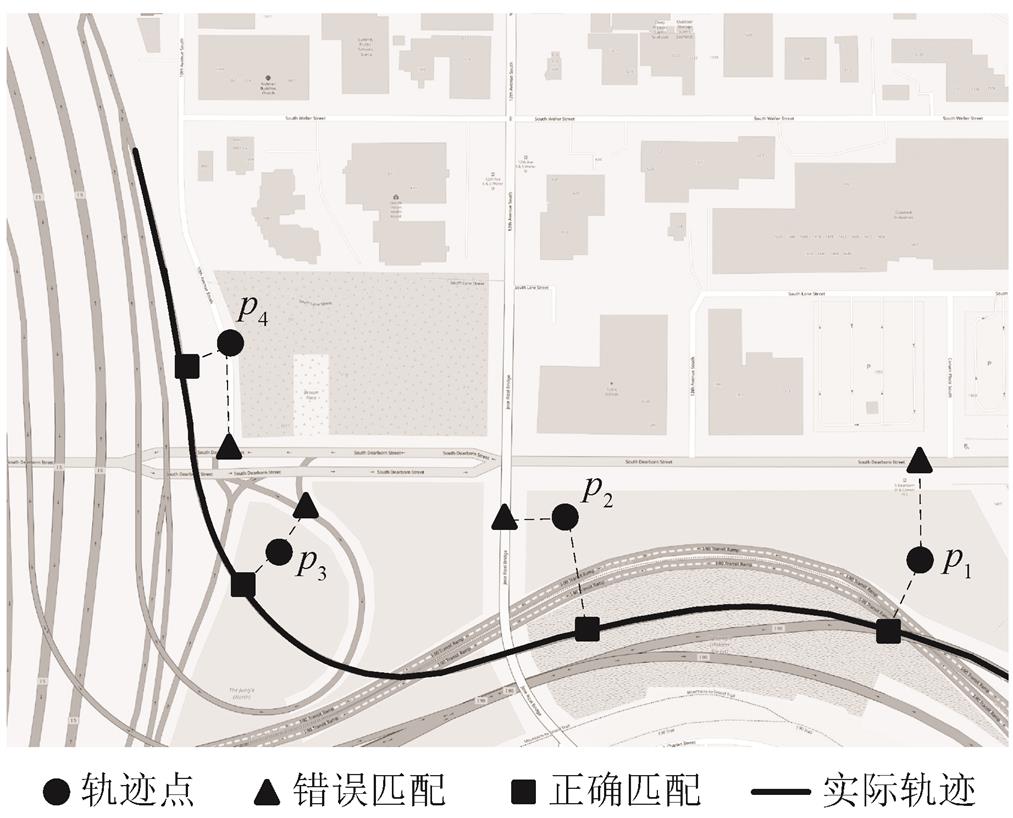
图1 地图匹配示意图
Fig. 1 Diagram of map matching
轨迹数据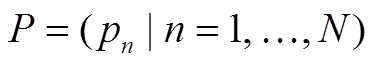 由一系列轨迹点组成, 使用一个五元组pi(lon, lat, s, β, t)表示轨迹点, lon和lat分别代表经纬度, s代表速度的大小, β代表当前行驶方向与正北方向的夹角, t代表时间戳。
由一系列轨迹点组成, 使用一个五元组pi(lon, lat, s, β, t)表示轨迹点, lon和lat分别代表经纬度, s代表速度的大小, β代表当前行驶方向与正北方向的夹角, t代表时间戳。
候选路段指当前轨迹点周边按照一定规则筛选出来的一些潜在的匹配路段, 在本文中指对于某个轨迹点 pi, 设置大小合适的缓冲区, 选取缓冲区内距pi最近的K条路段作为候选路段, 构成候选路段集合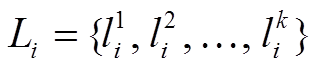 。候选点即某个候选路段上相应的匹配点, 在本文中指候选路段上与当前轨迹点之间欧氏距离最短的点, 构成候选点集合
。候选点即某个候选路段上相应的匹配点, 在本文中指候选路段上与当前轨迹点之间欧氏距离最短的点, 构成候选点集合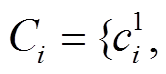
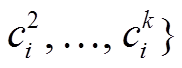
HMM 模型是关于时序的概率模型, 主要应用于语音识别及行为分析等领域中。在地图匹配问题中, 轨迹数据是可见的, 视为观测序列; 实际经过的道路不可见, 视为隐形的状态。使用 HMM 算法进行地图匹配, 解决的是预测问题, 即基于给定的观测序列, 得出条件概率最大的状态序列, 利用动态规划进行求解, 过程如下。
首先, 获取每一个轨迹点的候选路段, 将候选路段作为马尔科夫链的隐含状态, 每个隐含状态都有发射概率, 代表基于该状态得到观测点的概率。发射概率一般与轨迹点到候选路段的距离(d)有关, d值越小, 发射概率越大。
然后, 计算相邻轨迹点间候选路段对应的的状态转移矩阵。需要注意的是, HMM 具备两个性质: 无后效性与齐次性。无后效性指对于相邻的轨迹点对(pi, pi+1), pi+1的状态只与pi有关; 齐次性指状态转移概率与时间无关。对于一个轨迹序列, 利用已知的初始概率, 从第一个轨迹点到最后一个轨迹点不断递推地计算当前状态的联合概率, 可以得出最优路径的终点。基于动态规划思想, 最优路径的子路径也是最优路径, 通过回溯, 即可得出全局的最优路径。图 2 表示 HMM 应用于地图匹配的过程, 圆圈代表轨迹点的候选路段的集合(即隐含状态), 圆圈间的连线代表路段间的转移过程, 灰线代表最优路径。
本文在 Newson 等[9]提出地图匹配算法的基础上进行改进。Newson 算法的核心思想是, 假设司机选择最短路径行驶, 使用相邻轨迹点对应的候选路段间的最短路径距离计算传递概率, 路径长度越小, 传递概率越大。该算法中, 一方面由于候选路段较多, 候选路段间最短路径距离的计算量较大; 另一方面, 最优路径的计算考虑了所有的轨迹点信息, 导致其输出有一定程度的延时。因此, 该算法应用于在线地图匹配时, 存在时间效率不高以及匹配结果输出延时较长等问题。该算法基于轨迹点至候选路段的距离建立正态分布来计算发射概率, 未考虑轨迹点航向与路段方向的相似性。针对这两个问题, 本文引入可靠点的概念, 将轨迹分割成不同的增量, 对每个增量基于 HMM 进行地图匹配, 可以减少传递概率的计算量, 缩短匹配结果的输出延迟, 提高算法的时间效率。本文在发射概率的计算中同时考虑距离因素和方向因素, 能够保证增量两端的匹配准确性, 也提高了算法的准确性。
本文提出的算法主要包括 3 个部分: 数据预处理、轨迹分割及地图匹配。算法流程图如图 3 所示。数据预处理主要包括建立路网有向图和生成网格索引。轨迹分割的目的是生成轨迹增量, 主要步骤包括获取轨迹点候选集、计算发射概率以及判断可靠点。地图匹配主要包括计算传递概率、维特比算法求解及输出最优路径。

图2 HMM应用于地图匹配[13]
Fig. 2 HMM applied to map matching[13]

图3 地图匹配算法流程
Fig. 3 Map matching algorithm flowchart
在地图匹配前, 首先要对数据进行预处理。数据处理由两个部分组成: 建立路网有向图和生成网格索引。
3.1.1 建立路网有向图
路网数据一般为 shapefile 格式, 通过读取 shp文件和 dbf 文件, 获取道路的节点 ID、坐标信息及属性信息, 从而建立路网的有向图 G(V, E), 其中 V的元素为道路端点, E 的元素为道路路段。常用的描述有向图的方法有邻接矩阵和邻接链表。考虑到交通路网相对稀疏, 邻接链表占用内存空间较少, 本文采用邻接链表描述有向图。
3.1.2 生成网格索引
地图匹配过程中需要获取轨迹点的候选路段。由于简单地遍历整个道路网络耗费时间较长, 我们引入网格索引, 从而可以快速地获取候选路段。
网格索引的思想是, 将整个地图分成 M×N 个网格, 通过包含分析算法, 预先计算每个网格中包含(相交)的路段。本研究中, 我们将整个地图划分为 1000×1000 个的网格。网格索引在内存中的结构如图 4 所示。网格索引与路段数据通过路段 ID 相关联。
3.2.1 候选集获取
对轨迹点设置半径为 R 的缓冲区, 基于网格索引确定轨迹点所处的网格, 并查询以该网格为中心的 3×3 的网格内距该轨迹点最近的 K 条路段作为候选路段。过程如图 5 所示, 点 P 为轨迹点, A, B和 C 为路网中的路段, 在 P 周围 3×3 的网格中寻找与缓冲区(圆圈)相交的路段, 得到点 P 的候选路段为A。
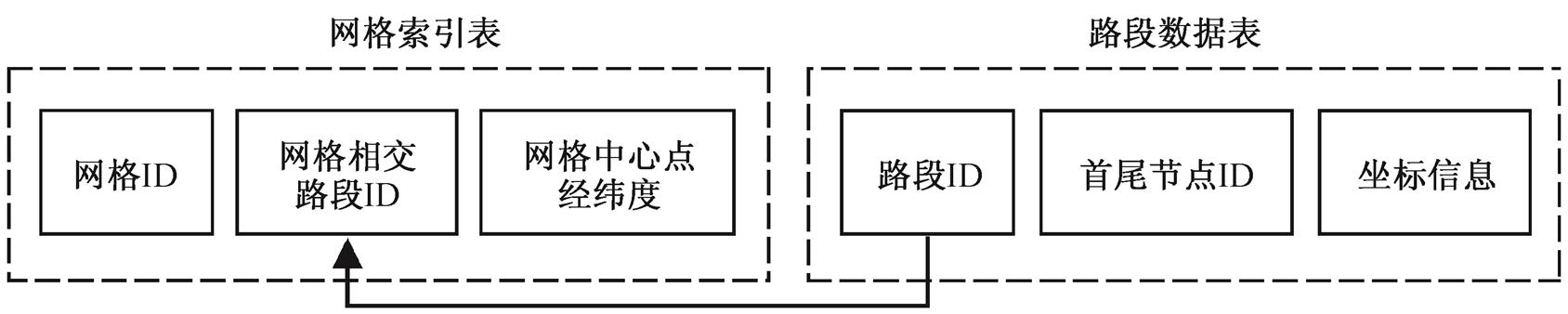
图4 网格索引结构
Fig. 4 Grid index structure
基于 R 和 K 两个参数, 获取初始的候选路段集后, 依据航向与路段方向的夹角进行筛选。若轨迹点方向与路段方向的夹角大于 90º, 则删除该路段。
3.2.2 发射概率计算
发射概率即在某种隐含状态下得到某种观测值的概率。本文中发射概率的计算主要分为两部分, 分别考虑距离因素和方向因素的影响。
Newson 等[9]认为观测到的轨迹点符合正态分布, 可以使用高斯函数来表达距离因素的发射概率, 相应的计算公式为
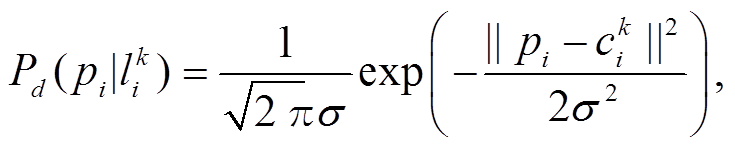 (1)
(1)其中, σ表示 GPS 的误差的标准差, 一般取值为 20 m; 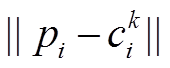 代表从轨迹点至候选路段的大圆距离。
代表从轨迹点至候选路段的大圆距离。
在 Newson 等[9]的算法中, 发射概率仅与距离因素有关。本文认为发射概率的计算也需要考虑方向权重。轨迹点pi的速度方向与路段的方向一般是一致的, 其瞬时速度方向与候选路段的夹角越小,通过轨迹点匹配得到路段的可能性越大。方向因素的发射概率的计算公式为
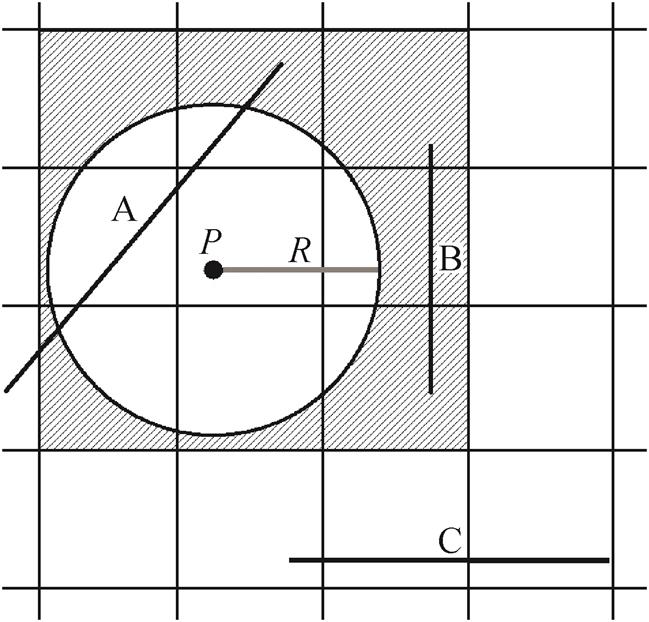
图5 获取候选路段示意图
Fig. 5 Candidate road acquisition
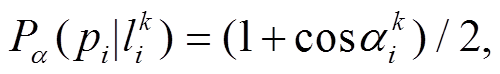 (2)
(2)其中, 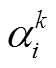 为速度方向与匹配路段的夹角。以正北方向为基准, 计算速度和匹配路段与正北方向的夹角分别为
为速度方向与匹配路段的夹角。以正北方向为基准, 计算速度和匹配路段与正北方向的夹角分别为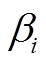 和
和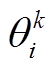 , 则的计算公式为
, 则的计算公式为
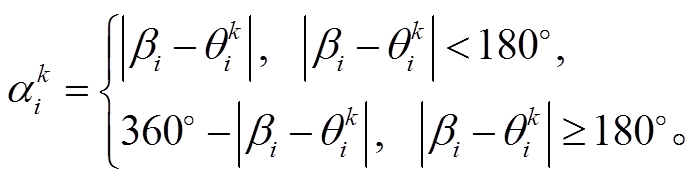 (3)
(3)
综合距离因素和方向因素, 发射概率的计算如下:
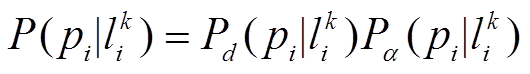 。 (4)
。 (4)3.2.3 可靠点判断
Newson 等[9]的地图匹配算法是对整条轨迹进行全局匹配, 当在线地图匹配中轨迹点数量较多时, 该算法输出时延较长。针对此问题, 本文利用可靠点将轨迹分割成不同的增量, 能够保证轨迹增量两端匹配的准确性。
可靠点的定义如下: 对于轨迹点 pi 及其候选路段集, 如果路段集的大小为 1, 则认为 pi 是可靠点; 对候选路段的发射概率进行排序, 得到发射概率排名前两位的候选路段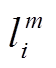 和
和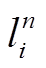 , 对应的发射概率更大, 若两路段的发射概率满足式(5), 则认为 pi 也是可靠点, 并删除其候选路段集中最大发射概率对应路段之外的路段, 从而降低算法的不确定性, 同时也减轻了状态转移概率的计算量。
, 对应的发射概率更大, 若两路段的发射概率满足式(5), 则认为 pi 也是可靠点, 并删除其候选路段集中最大发射概率对应路段之外的路段, 从而降低算法的不确定性, 同时也减轻了状态转移概率的计算量。
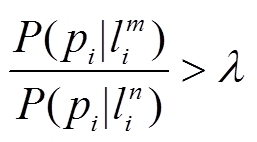 , (5)
, (5)其中, 可靠点参数 λ是一个经验参数, 其作用是对可靠点进行区分。可靠点的获取相当于对传统的点到线的地图匹配算法的改进。传统的基于点到线的地图匹配算法是基于距离和方向因素构建权重函数, 将权重最大的点作为匹配点, 具备较好的准确率。可靠点的获取是在此设置阈值 λ, 思路是基于数据统计及处理经验, 保证了可靠点处的匹配准确率。λ值的选取将在实验部分进行分析。
3.3.1 传递概率
状态转移概率代表从一个候选路段移动到另一个候选路段的过程。下面进行轨迹增量内状态转移概率矩阵的计算。本文中传递概率的计算基于一个假设: 出租车司机一般选择最近的路线行驶, 前后路段间的路网距离越小, 其传递概率越大。
传递概率公式为
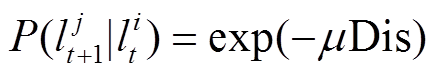 , (6)
, (6)其中, 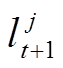 和
和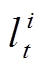 分别为第 t+1 个轨迹点和第 t 个轨迹点对应的候选路段,
分别为第 t+1 个轨迹点和第 t 个轨迹点对应的候选路段, 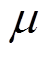 是人为设定的参数, Dis 代表从候选路段间的实际路网距离。区别于使用传统的BFS 算法(如 Dijkstra 算法), 本文使用启发式的 A*算法进行路网距离的计算。A*算法不需要遍历路网中所有的路段, 其距离估算值与实际值越接近, 算法运行速度越快, 效率越高。
是人为设定的参数, Dis 代表从候选路段间的实际路网距离。区别于使用传统的BFS 算法(如 Dijkstra 算法), 本文使用启发式的 A*算法进行路网距离的计算。A*算法不需要遍历路网中所有的路段, 其距离估算值与实际值越接近, 算法运行速度越快, 效率越高。
3.3.2 维特比算法输出最优路径
基于隐马尔科夫模型寻找最优的匹配路径属于预测问题, 需要使用维特比算法求解。维特比算法常用于语音识别、计算语言学等领域, 其思想是基于传递概率和观察概率, 逐步求解状态的联合概率, 并记录当前隐含状态的前一个状态, 最终得到最优路径的终点。基于记录的前一个状态信息, 回溯得到整条最优路径。
如果对匹配的实时性要求不高, 可将整个增量进行全局匹配。在实时性要求较高的场景中, 需要设置一个阈值 max_size, 使用滑动窗口在增量中进行匹配, 当窗口大小达到阈值时, 则输出当前窗口内的匹配结果, 并移动窗口, 处理新的数据。
地图匹配使用的维特比算法主要包括两部分: 最优路径终点的获取和回溯。算法的伪代码如下。
输入: 轨迹数据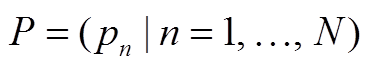
输出: 匹配的路段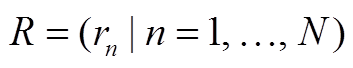
1 令func[ ]为当前状态对应的联合概率, prev[ ]为
当前状态的前一个状态
2 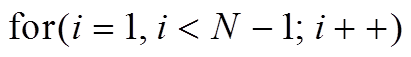
3 获取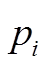 对应的候选路段集
对应的候选路段集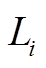
4 获取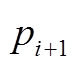 对应的候选路段集
对应的候选路段集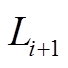
5 for eachl1 inLi+1
6 计算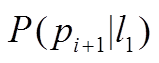
7 for eachl2in Li
8 if i=1 //初始化
9 计算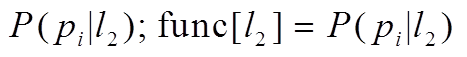 ;
;
10 计算传递概率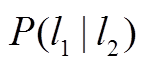
11 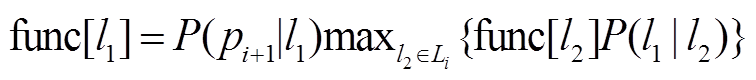
12 
13 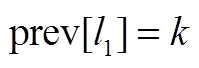
14 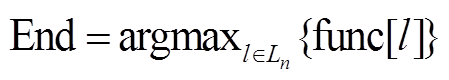 //获取全局最优路径
//获取全局最优路径
的终点
15 R. append (End)
16 for
17 End=pre[End]
18 R. append (End) //回溯过程
19 R. reverse ( )
20 return R
本文使用的数据集是由美国微软研究院提供的公开浮动车数据, 路网数据为西雅图市的道路交通路网, 共有 158167 条路段, 浮动车轨迹数据有 7531个轨迹点, 原始时间间隔为 1 s,在实验中设置轨迹数据的采样频率为 30 s,采样后包含 249 个轨迹点。由于数据本身不包含航向信息,在实验中将所有候选点的方向因素对应的发射概率设为固定值 1。图 6 为在开源 GIS 软件 QGIS 中显示的路网数据与轨迹数据。
首先设置参数: 缓冲区半径 R 设为 200m, 候选集的路段个数K设为 4, 标准差 σ设为 20m, 传递概率计算用到的参数 μ设置为 5。为了合理地选择式(6)中可靠点经验参数 λ, 使用不同的 λ值分割轨迹, 并评估可靠点处的匹配正确率, 实验结果如图 7 所示, 当 λ=1 时,可靠点的匹配准确率相对较低,随着 λ值的增加, 可靠点的匹配准确率保持在一个较高的水平,当 λ=5 时, 可靠点匹配的错误率小于 1.5%。在下面的实验中将λ值设为5。
地图匹配的准确率用式(8)计算:
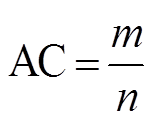 , (7)
, (7)
其中, AC 代表准确率, m 代表正确匹配到对应路段的轨迹点的个数, n代表轨迹点的总数。
图 8 和 9 分别是本文算法在立交桥或密集道路两种情况下的匹配效果, 红点代表原始轨迹点, 蓝线代表匹配结果。可以看到,本文算法在两种情况下都有较好的效果。
图6 路网数据和轨迹数据
Fig. 6 Road network data and trajectory data
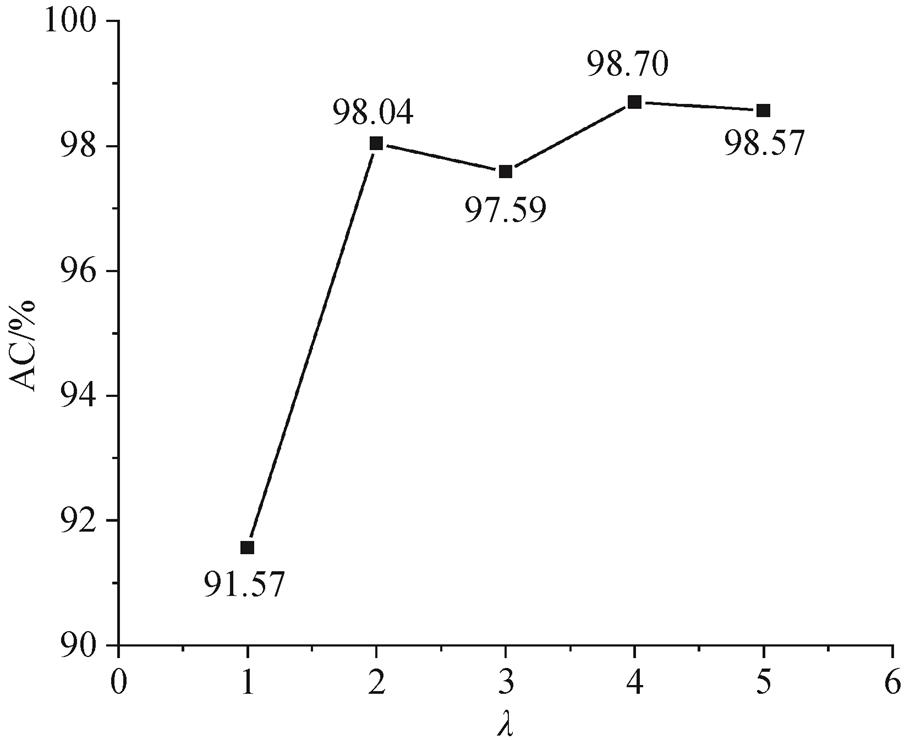
图7 可靠点匹配准确率随可靠点参数λ的变化
Fig. 7 Reliable point’s matching accuracy varies with λ
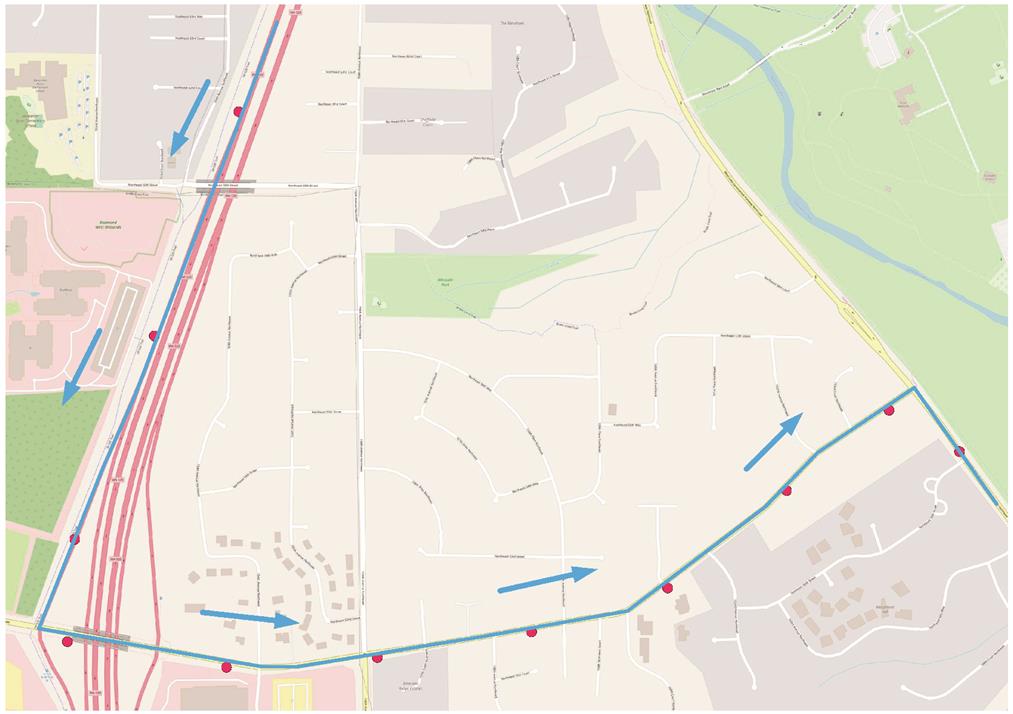
图8 立交桥路段处地图匹配结果
Fig. 8 Map matching result at the overpass section
对比本文算法与传统 HMM 地图匹配算法[9]的准确率, 结果见图 10。灰色折线代表传统 HMM 算法的结果(不对轨迹进行分割), 黑色折线代表本文算法的结果。可以看出, 随着 K 值增大, 本文算法的准确率不断提高, 并在 K= 4 时达到最高值, 当K= 5 时, 准确率有所下降。然而, 传统 HMM 算法的准确率受 K 值影响不大。原因在于, 传统 HMM算法是对整条轨迹进行计算, 匹配结果的不确定性较大, 而本文算法基于可靠点分割, 使得轨迹增量中包含的轨迹点数量较少, 匹配结果的不确定性也较小, 因此, 合适的 K 值能够在一定程度上提高算法的准确率, 但 K 过大时(如 K = 5), 候选集中存在距离轨迹点较远的路段, 会对匹配结果产生干扰。与传统的 HMM 算法相比, 本文算法的匹配准确率更优。
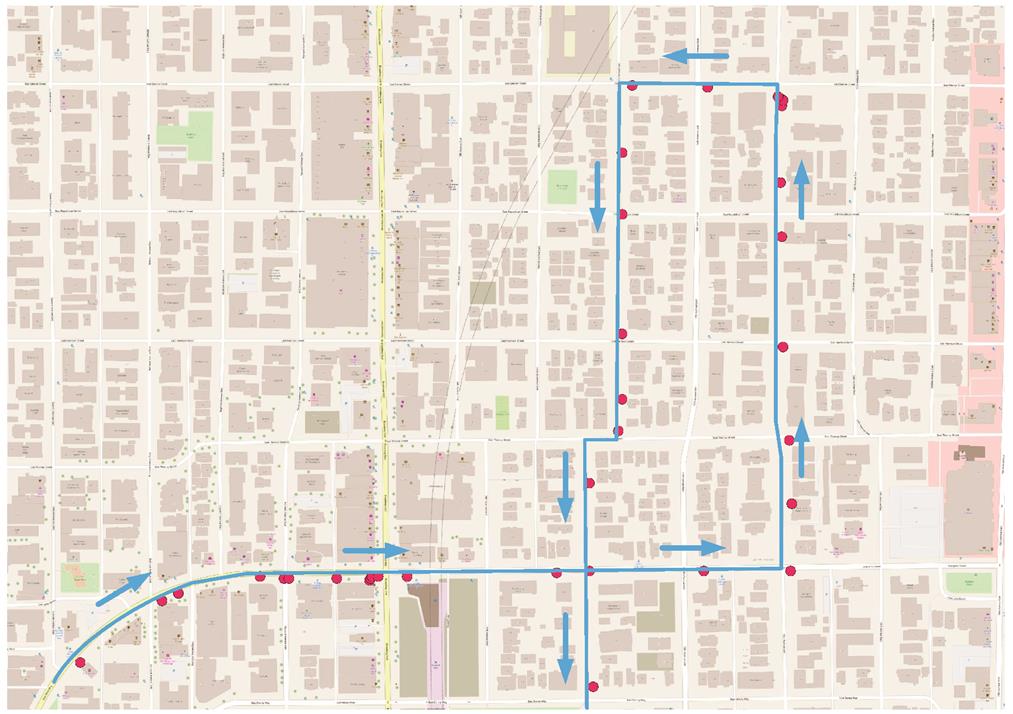
图9 密集道路处地图匹配结果
Fig. 9 Map matching result on the dense roads
对比本文算法与传统 HMM 算法的计算效率, 结果见图 11。可以看出, 随着代表候选集大小的参数 K值增大, 单点匹配所需时间不断增加。由于可靠点分割减少了传递概率的计算量, 本文算法在时间效率上也优于传统HMM算法。
本文针对在线地图匹配问题, 提出基于 HMM模型改进的地图匹配算法, 在候选集计算过程和最短路径计算中分别使用网格索引和 A*算法, 并引入可靠点的概念, 将轨迹分割成不同的增量, 对每个增量基于 HMM 算法进行地图匹配, 减少了传递概率的计算量和匹配结果的输出延迟, 提高了算法的时间效率。提出了基于多重因素权重(距离、方向)计算发射概率的方法, 并利用可靠点参数来保证轨迹增量起始点处的匹配准确性。基于真实数据对算法进行验证, 证明算法适用于立交桥与密集路段处的地图匹配。与传统HMM算法相比, 本文算法的准确性和时间效率更优。
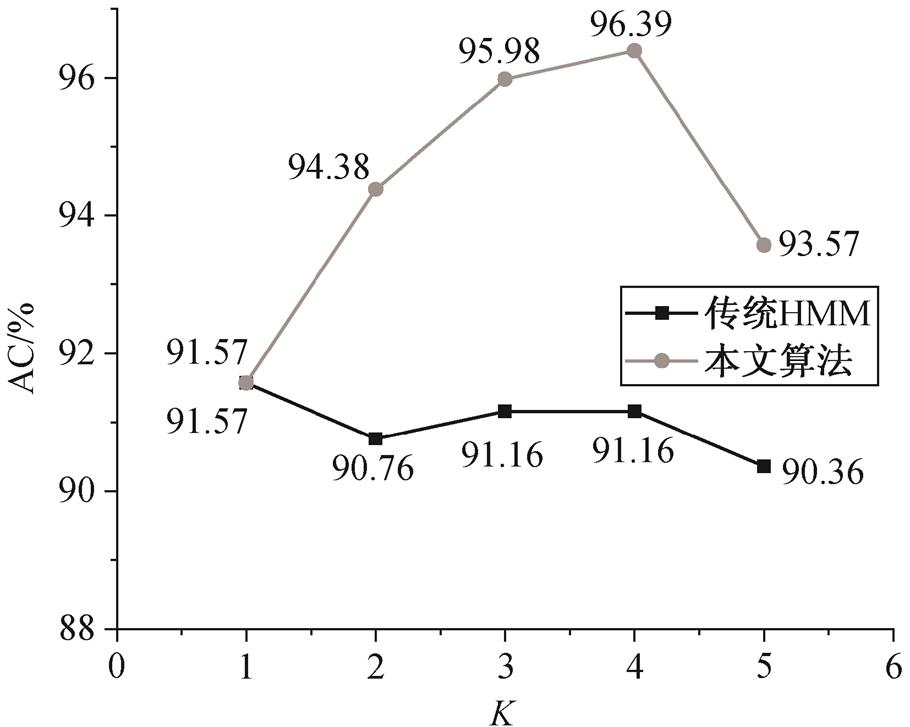
图10 匹配准确率对比
Fig. 10 Matching accuracy comparison
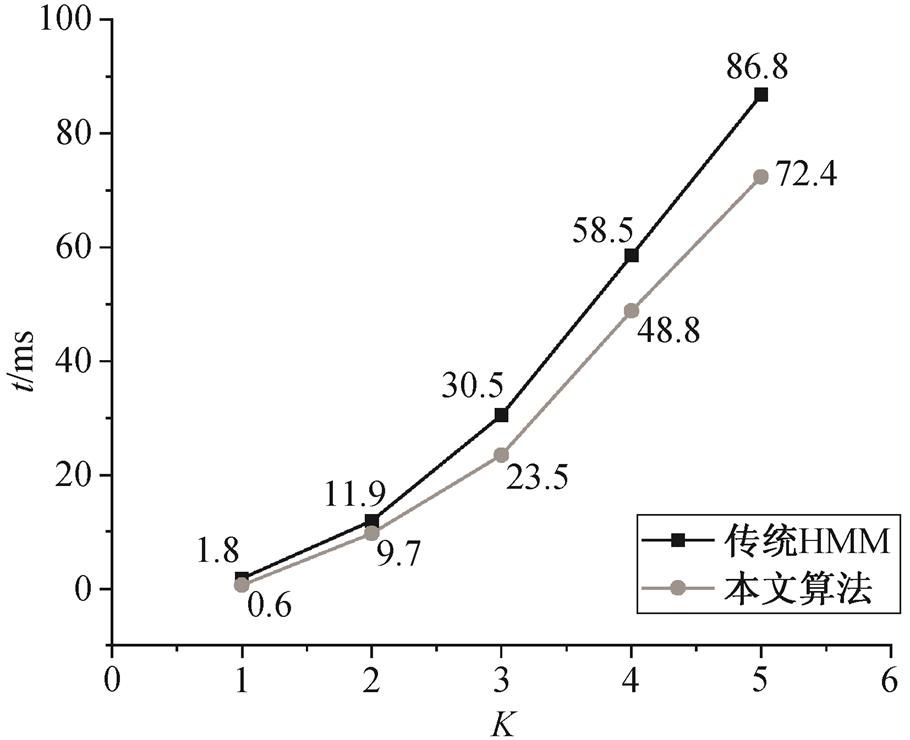
图11 匹配时间效率对比
Fig. 11 Matching time efficiency comparison
本研究中未对轨迹点的速度和匹配路段的限速进行分析, 后续研究中可以考虑加入路段限速信息, 并基于并行计算平台 CUDA (compute unified device architecture)进行并发编程; 也可以引入机器学习的方法, 综合历史轨迹数据和当前轨迹数据进行地图匹配。
参考文献
[1]Yuan J, Zheng Y, Xie X. Driving with knowledge from the physical world // Proceedings of the 17th ACM SIGKDD International Conference on Knowle-dge Discovery and Data Mining. San Diego, 2011: 316‒324
[2]Chen C,Zhang D, Castro P S. Isolation-based online anomalous trajectory detection. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(2):806‒818
[3]Li X, Han J, Lee J, et al. Traffic density-based discovery of ho routes in road networks // Advances in spatial and temporal databases. Berlin: Springer, 2007: 441‒459
[4]Zheng Y, Liu Y, Yuan J. Urban computing with taxi-cabs // Proceedings of the 13th International Confe-rence on Ubiquitous Computing. Beijing,: ACM, 2011: 89‒98
[5]Zhang J T. Smarter outlier detection and deeper understanding of large-scale taxi trip records: a case study of NYC // Proceedings of the ACM SIGKDD International Workshop on Urban Computing. Beijing, 2012:157‒162
[6]袁晶. 大规模轨迹数据的检索、挖掘及应用[D]. 合肥: 中国科学技术大学, 2012
[7]李清泉, 胡波, 乐阳. 一种基于约束的最短路劲低频浮动车数据地图匹配算法. 武汉大学学报(信息科学版), 2013, 38(7): 805‒808
[8]Ochieng W Y, Quddus M, Noland R B. Map matching in complex road networks. Revista Brasileira de Cartigrafia, 2003, 55(2): 1‒14
[9]Newson P, Krumm J. Hidden Markov map matching through noise and sparsenes // ACM Sigspatial International Symposium on Advances in Geographic Information Systems. Seattle, 2009: 336‒343
[10]Brakatsoulas S, Pfoser D, Salas R, et al. On map-matching vehicle tracking data // Proceeding of the 31st VLDB Conference. Trondheim, 2005: 853‒864
[11]Alt H, Efrat A, Rote G, et al. Matching planar maps. Journal of Algorithms, 2003, 49: 262‒283
[12]刘培. 基于浮动车数据的地图匹配算法研究[D]. 北京: 北京交通大学, 2007
[13]Goh C Y, Dauwels J, Mitrovic N, et al. Online map-matching based on Hidden Markov model for real-time traffic sensing applications// International IEEE Conference on Intelligent Transportation Systems. Anchorage: IEEE, 2012:776‒781
An Improved Map Matching Algorithm Based on HMM Model
LIU Min, LI Mei†, XU Xiaoyu, MAO Shanjun
School of Earth and Space Sciences, Peking University, Beijing 100871; † Corresponding author, E-mail: mli@pku.edu.cn
Abstract For it’s difficult to guarantee the accuracy and time efficiency of online map matching simultaneously, an improved online map matching algorithm based on the HMM model is proposed. Different from other global or local algorithms, the algorithm introduces reliable point to divide the trajectory, thus reducing the calculation of transition probability and the output delay of matching results. Also, the method of calculating the transmitting probability by combining distance factor and directional factor is proposed. The algorithm is verified using floating car trajectory data in Seattle. Experimental results show that the proposed algorithm outperforms the traditional HMM map matching algorithm both in accuray and time efficiency, which can meet the requirement of online map matching.
Key words map matching; HMM; reliable point; transition probability;transmitting probability
中图分类号 TP75
doi: 10.13209/j.0479-8023.2018.038
国家重点研发计划(2016YFC0803108)资助
收稿日期: 2017-11-15;
修回日期: 2018-01-02;
网络出版日期: 2018-06-15